
Digital theft has been a big problem for everyone since the internet started, as anyone on the internet can take your content, image, and voice, claim it as their own, and profit from it. With the technological updates, manually stealing someone’s content became an automatic process using various techs and tools. Nowadays, so many people are using content scraping or blog scraping tools to steal content from popular publishers and again publish it on their websites as their own.
Content Scraping is a process in which a person or bot copies content from your website by iterating through your website data tress. Imagine you’ve created a piece of content with your hard work, and someone stole it without your permission. Later they published it, monetized it, and in some cases, even noted that the site with stolen content outranked the original post and stole the audience.
It is frustrating for the owner to see someone benefiting from your hard work, so we will cover how to catch and prevent blog content scraping.

What is Blog Content Scraping?
Blog content scraping, also known as “content stealing”, is an act of extracting or copying content from various websites and republishing it on your own website without credit or permission. Primarily content scraping is done by automatically using plugins or bots. This is usually done without much effort to get traffic for lead generation and monetize the content. Content scraping is a big problem for original publishers because the bigger you grow, the more you see content scraping. Content scraping is illegal and against copyright laws, but still, it is happening a lot as it has become effortless with the help of automated tools.Why Does Content Scraping Happen?
Content scraping is one of the most common problems website owners faces. And the primary reason for content scraping is to gain traffic with little effort because traffic equals money. Also, content scraping can be used to build a blog to gain customers and credibility on the Internet. There are many other reasons behind content scraping, and below are the most common reasons you will see:- Lower Efforts: The main motivation behind content scraping is to get more traffic with less effort. Writing original content takes a lot of dedication, research, and writing, but copying, combining and republishing from multiple sources takes less effort. And with the help of automated content scraping tools, plugins, and bots, it becomes easier for everyone.
- For Lead Generation: Lead generation is another reason behind content scraping. We often see small businesses, individuals such as lawyers, real estate agents and many others using content scraping tools to enrich their websites with minimal effort. The primary reason for creating quality content is to show your expertise and credibility to attract customers or lead generation.
- Advertisement Revenue and Affiliate Commission: So many people use content scraping tools to create content and enrich their websites. And their primary reason is to get high traffic and later use it to generate advertising revenue and promote third party products for commission.
Ways to Prevent Content Scraping
Catching and stopping content scraping is a time-consuming task that requires a lot of effort, but there are several measures you can follow to stop content scraping.Rate Limiting and Blocking IPs
Limiting access and blocking IP addresses is one of the best ways to prevent content scraping. Rate limiting is a way of controlling sent and received requests, so an IP cannot send too many requests at once. Unfortunately, limiting access doesn’t always stop content scrapers, so you’ll have to opt for more aggressive strategies, such as blocking IPs manually or automatically. Blocking IPs manually is not easy, so using third-party WordPress firewall plugins such as MaxCDN, sucuri, and Cloudflare is recommended. But if you have good knowledge or a team of experts, you can also choose manual IP blocking. But first, you should discover the content scraper IP address by analyzing the access log with the help of the number of requests sent and received from an IP. When you find out the IP, you can block it by editing the htaccess file and inserting the below line:Deny from 94.66.58.135
Make sure to replace the IP address with the content scraper IP address. When you add the above line and save the file again, the scraper will not be able to access your site.Adding Copyright Trademark
Adding a copyright tag below on your website footer will inform your user that all published content is copyrighted and reserved. Therefore, you only use them with taking permission from the owner. This process works like magic because anyone can use your content for their own benefit if you do not add a copyright notice. However, it is not much helpful if scrapers do it intentionally. You can use simple words with a dynamic year, like “Copyright Reserved ©️2023” in the footer. The image below shows the copyright tag added to our website:
Adding Watermark
Adding a watermark also helps you to protect your images from content scrapers, as they may not want to share a watermarked image on their website. The best way to add a watermark on your image is to add your site logo or your site name. Ultimately, this little trick will reduce image theft by up to 50% because scrapers always try to share content that looks like their own after publication.Using Captcha
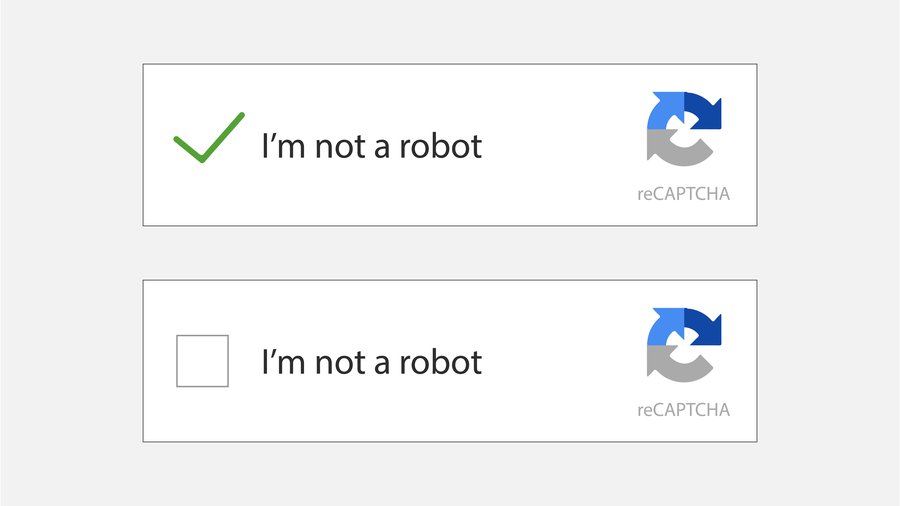
If you still suspect unwanted bots and scrapers are scraping your website, you can always use CAPTCHA. Captcha is a technique that verifies the user by giving some simple tests and approval based on whether you are a human or a bot. Captcha refers to the Completely Automated Public Turing test to determine whether the user is a bot or human. Captchas are useful for preventing content scrapers but also annoying for real users. Several CAPTCHA plugins are available on WordPress, such as Math CAPTCHA, Google CAPTCHA etc. Using this method dramatically reduces the content scraping done by bots.
RSS Feed
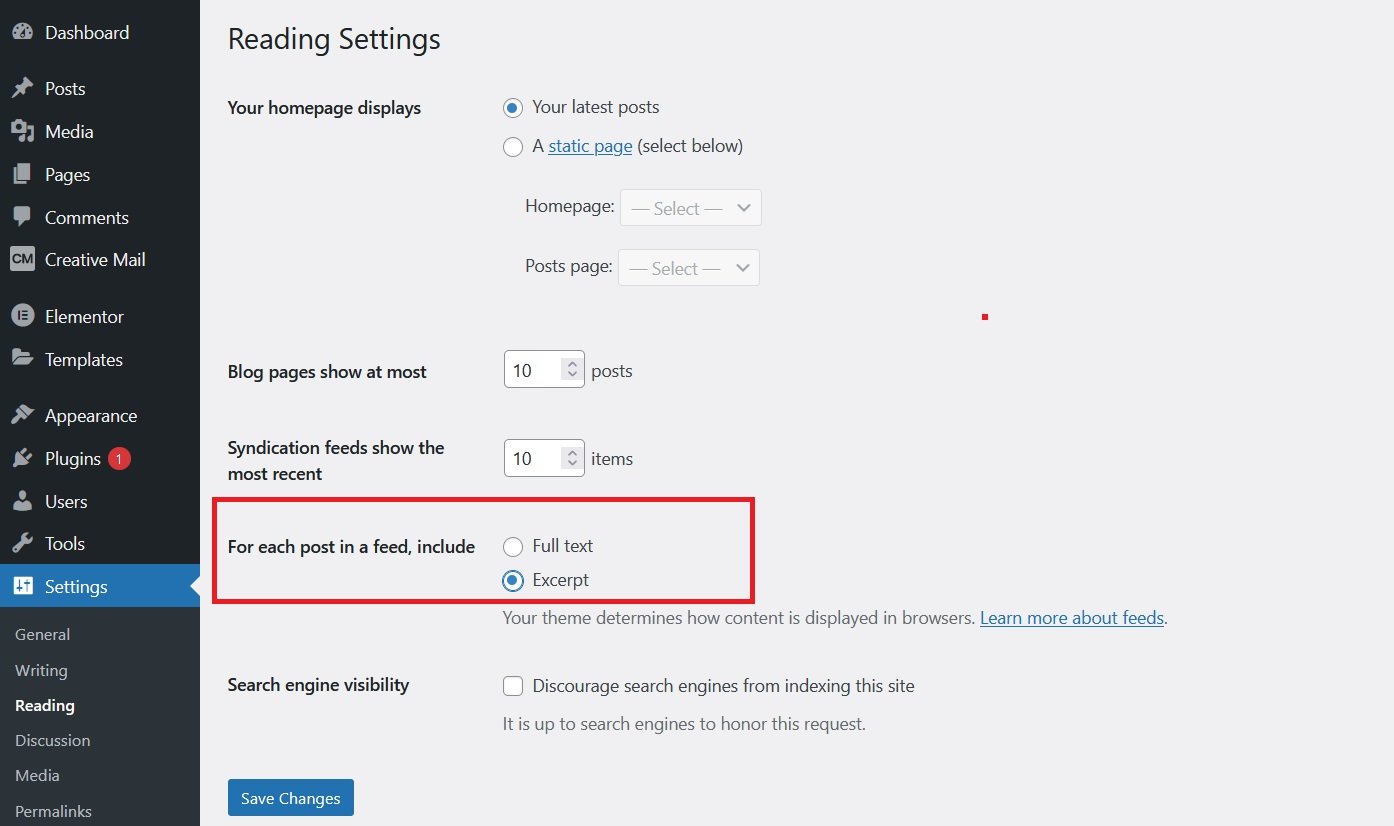
Changing the RSS feed from full text to Excerpt ultimately reduces scraping. The default setting for an RSS feed is the full text, meaning that the entire post content is included in the RSS feed, and a content scraper can copy it completely by targeting only the RSS feed. This doesn’t mean you have to stop using the RSS feed but be sure to change the default settings from full text to Excerpt so that the scraper can only copy the summary of the post content. To change the RSS feed setting, login inside the WordPress Admin Dashboard. You will see the Settings option on the left sidebar navigation menu, hover over it, and it will show the submenu which contains the “Reading” option. Click on it. Then you will notice reading settings, so change the “For each post in a feed, include ” to Except.

